Running your pipeline
You can upload and run your pipeline directly from the pipeline editor. Use either your newly created pipeline or the provided 4-train-save.pipeline file.
-
You set the S3 storage bucket keys, as described in Configuring the connection to storage.
-
You configured a pipeline server, as described in Enabling AI pipelines.
-
If you created your workbench before the pipeline server was available, you stopped and restarted the workbench.
-
In the JupyterLab pipeline editor toolbar, click Run Pipeline.
-
Enter a name for your pipeline.
-
Verify that the Runtime Configuration: is set to
Pipeline. -
Click OK.
NOTE: If you see an error message stating that "no runtime configuration for Pipelines is defined", you might have created your workbench before the pipeline server was available. To address this error, you must verify that you configured the pipeline server and then restart the workbench.
-
In the OpenShift AI dashboard, open your project and expand the newly created pipeline.

-
Click View runs.

-
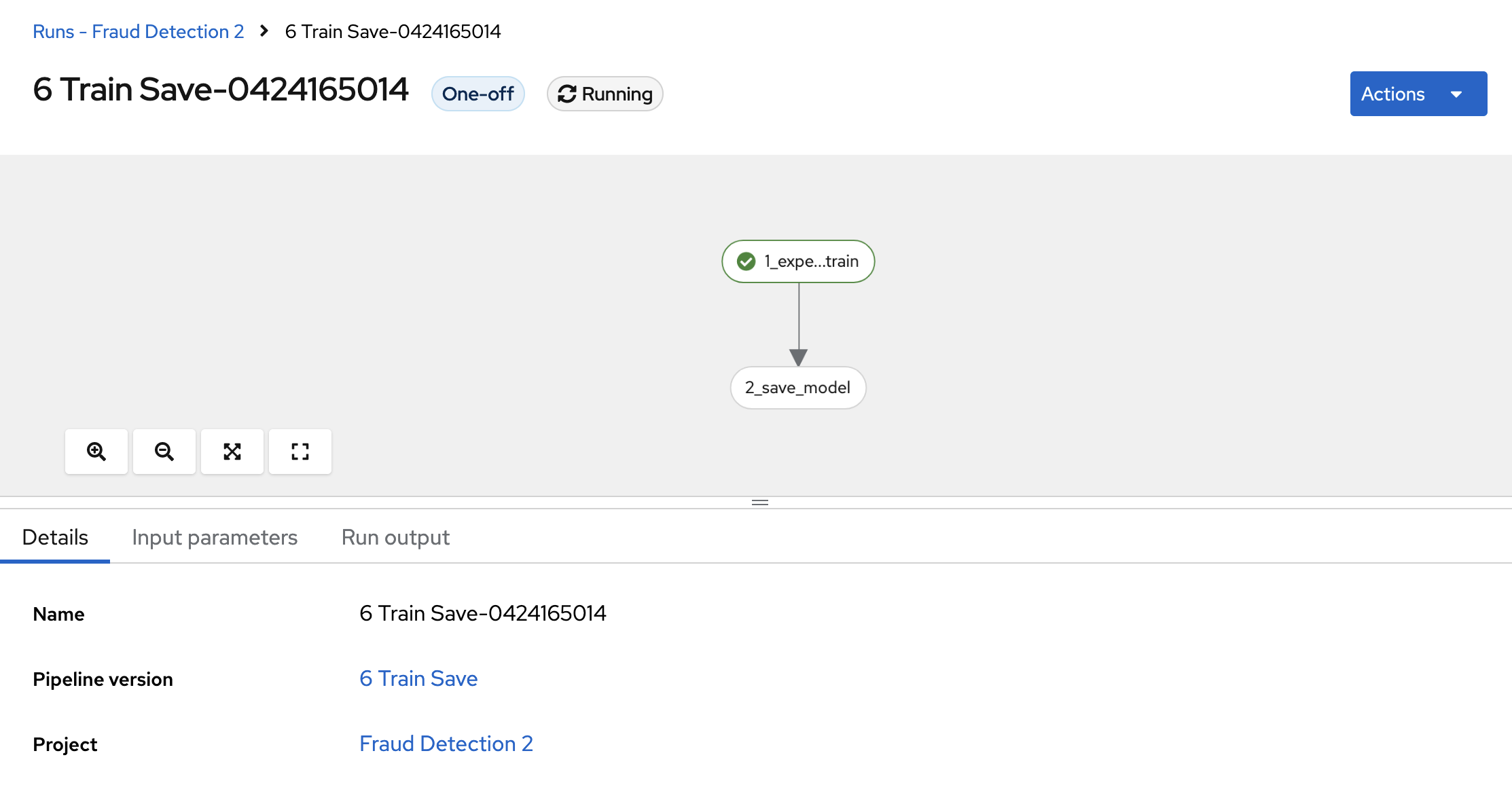
Click your run and then view the pipeline run in progress.
-
The
models/fraud/1/model.onnxfile is in your S3 bucket.
-
Serve the model, as described in Preparing a model for deployment.