(Optional) Creating connections to your own S3-compatible object storage
| Skip this procedure if you completed the steps in Running a script to install local object storage buckets and create connections. |
If you have existing S3-compatible storage buckets that you want to use for this workshop, you must create a connection to one storage bucket for saving your data and models. If you want to complete the pipelines section of this workshop, create another connection to a different storage bucket for saving pipeline artifacts.
When you create a connection to storage in a production-ready project, follow these security guidelines:
-
Store credentials in secrets rather than plaintext.
-
Use least-privilege access policies for S3 buckets.
-
Rotate access keys periodically.
To create connections to your existing S3-compatible storage buckets, you need the following credential information for the storage buckets:
-
Endpoint URL
-
Access key
-
Secret key
-
Region
-
Bucket name
If you do not have this information, contact your storage administrator.
-
Create a connection for saving your data and models:
-
In the OpenShift AI dashboard, navigate to the page for your project.
-
Click the Connections tab, and then click Create connection.
-
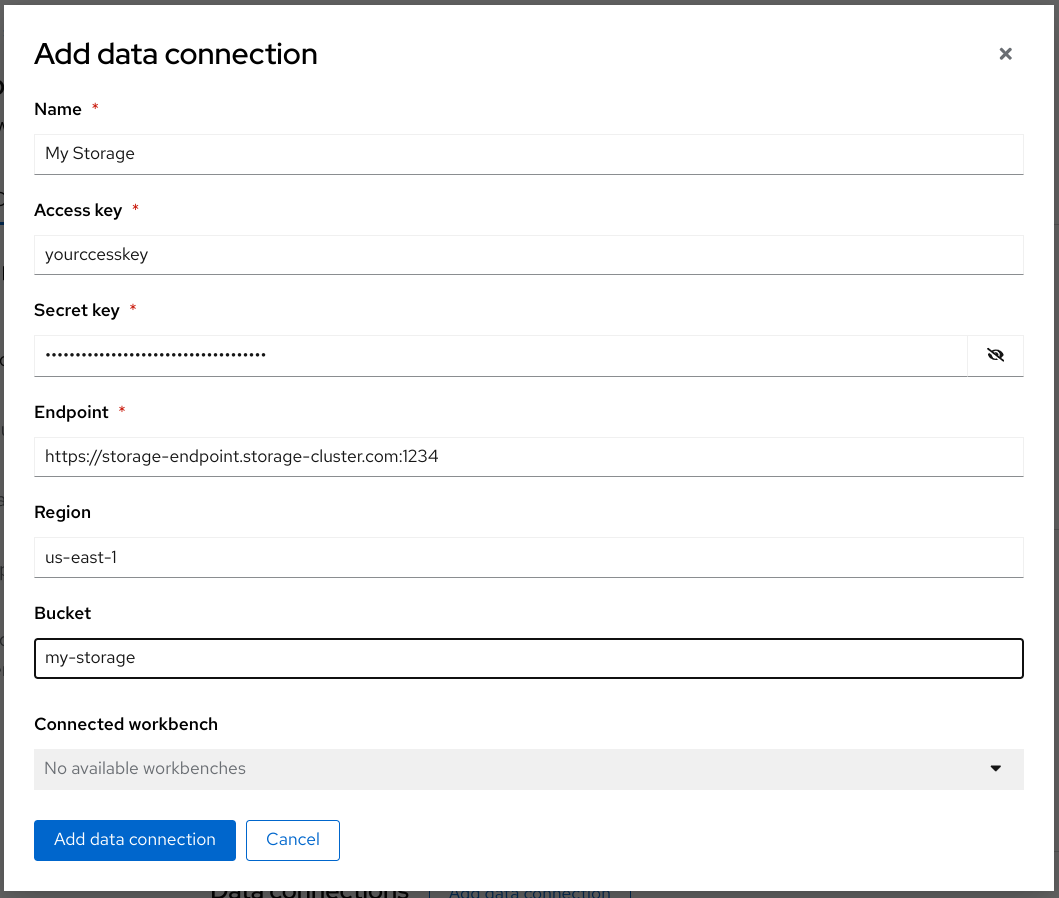
In the Add connection modal, for the Connection type select S3 compatible object storage - v1.
-
Complete the Add connection form and name your connection My Storage. This connection is for saving your personal work, including data and models.
-
Click Create.
-
-
Create a connection for saving pipeline artifacts:
If you do not intend to complete the pipelines section of the workshop, you can skip this step. -
Click Add connection.
-
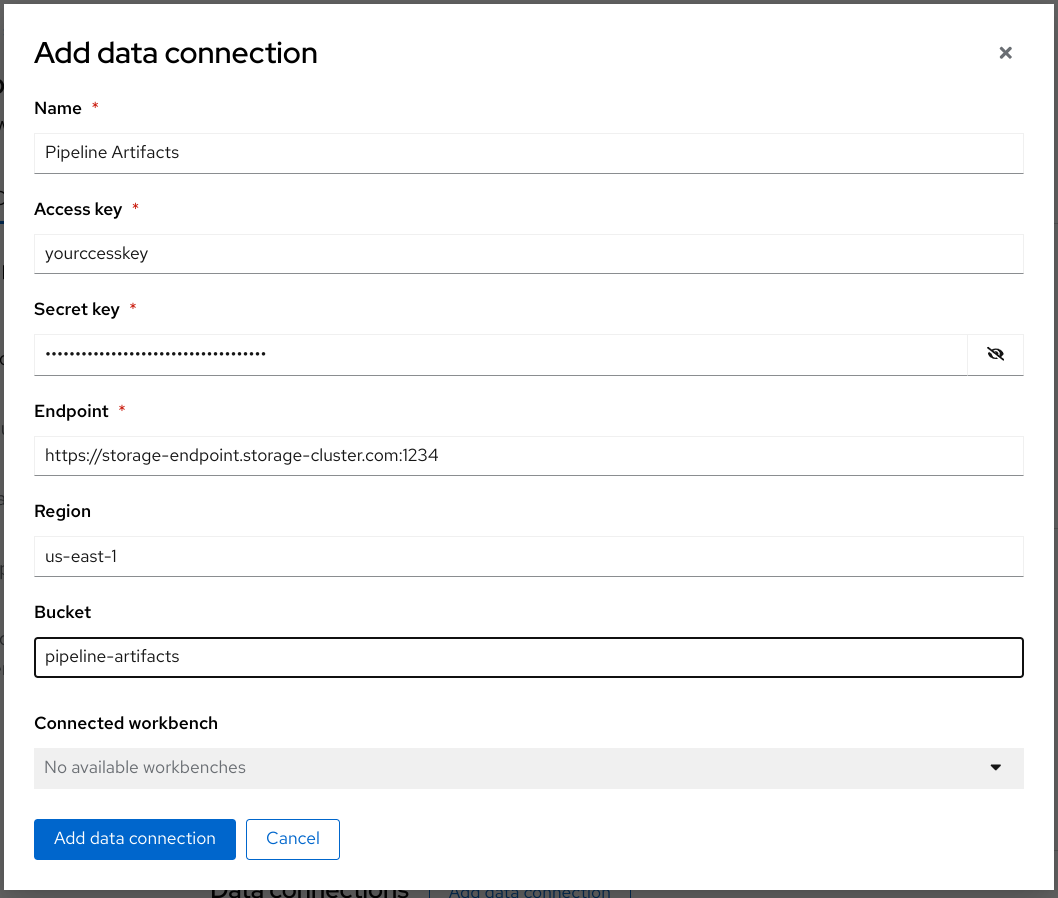
Complete the form and name your connection Pipeline Artifacts.
-
Click Create.
-
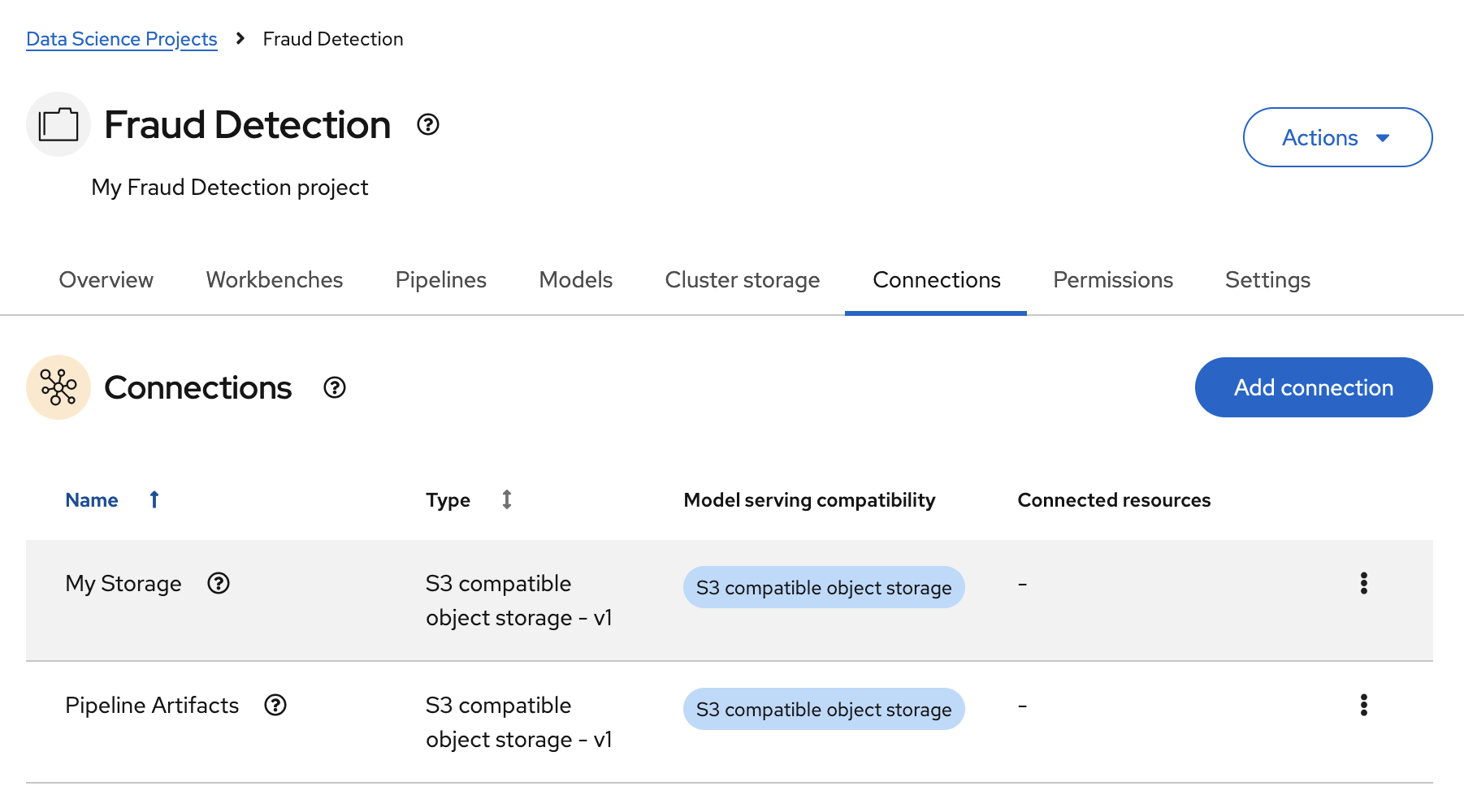
In the Connections tab for the project, check to see that your connections are listed.
|
If your cluster uses self-signed certificates, your OpenShift AI administrator might need to provide a certificate authority (CA) to securely connect to the S3 object storage, as described in Accessing S3-compatible object storage with self-signed certificates (Self-Managed). |
-
Decide whether you want to complete the pipelines section of this workshop. With OpenShift AI pipelines, you can automate the execution of your notebooks and Python code. You can run long training jobs or retrain your models on a schedule without having to manually run them in a notebook.
If you want to complete the pipelines section of this workshop, go to Enabling AI pipelines.
-
Decide whether you want to complete the Distributing training jobs with the Training Operator section of this workshop. In that section, you implement a distributed training job by using Kueue for managing job resources.
If you want to complete the Distributing training jobs with the Training Operator section of this workshop, go to Setting up Kueue resources.
-
Otherwise, skip to Creating a workbench.