Enabling data science pipelines
You must prepare your workshop environment so that you can use data science pipelines.
| If you do not intend to complete the pipelines section of this workshop you can skip this step and move on to the next section, Setting up Kueue resources. |
Later in this workshop, you implement an example pipeline by using the JupyterLab Elyra extension. With Elyra, you can create a visual end-to-end pipeline workflow that executes in OpenShift AI.
-
You have installed local object storage buckets and created connections, as described in Storing data with connections.
-
In the OpenShift AI dashboard, on the Fraud Detection page, click the Pipelines tab.
-
Click Configure pipeline server.
-
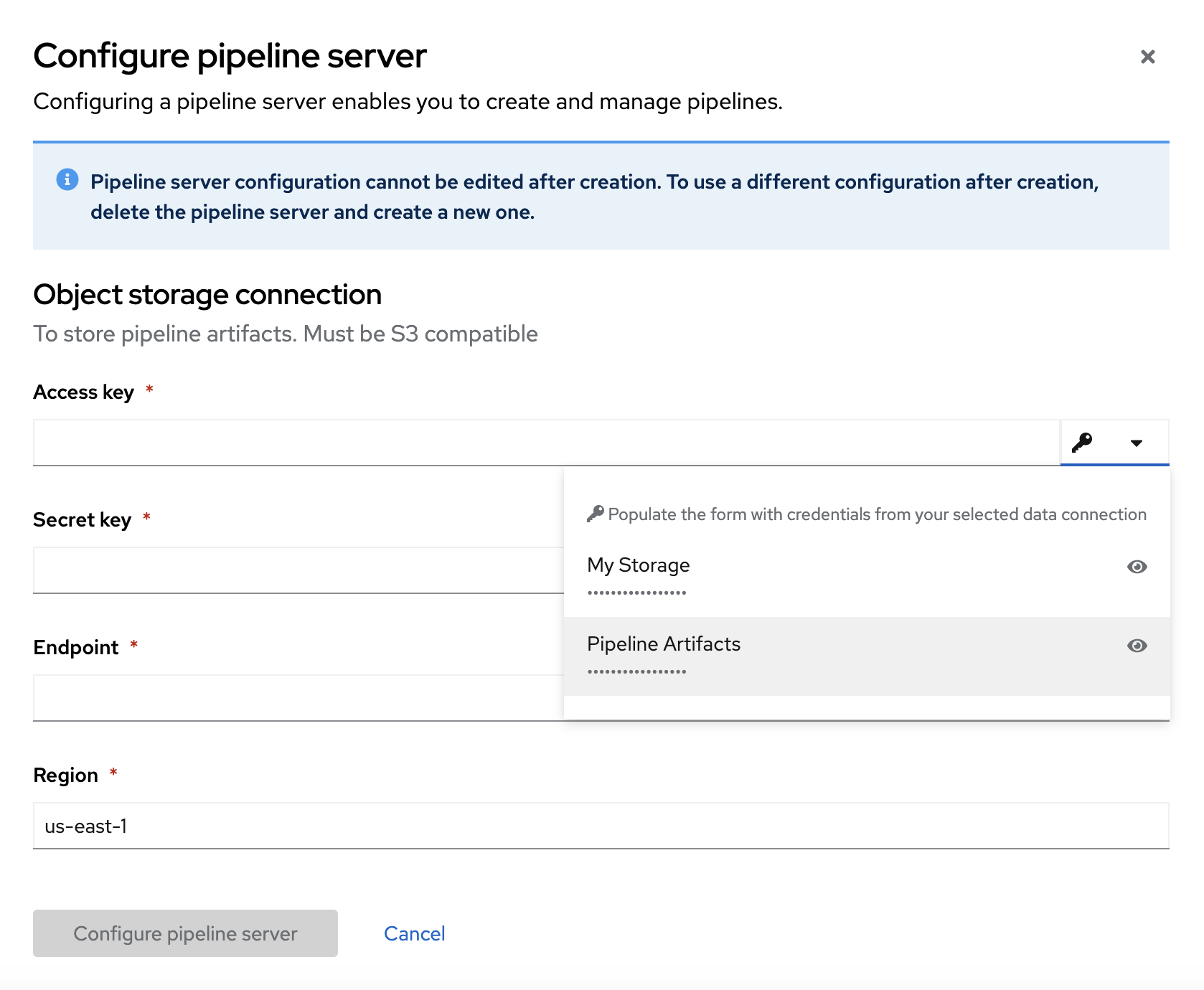
In the Configure pipeline server form, in the Access key field next to the key icon, click the dropdown menu and then click Pipeline Artifacts.
The Configure pipeline server form autofills with credentials for the connection.
-
In the Advanced Settings section, leave the default values.
-
Click Configure pipeline server.
-
Wait until the loading spinner disappears and Start by importing a pipeline is displayed.
You must wait until the pipeline configuration is complete before you continue and create your workbench. If you create your workbench before the pipeline server is ready, your workbench cannot submit pipelines to it.
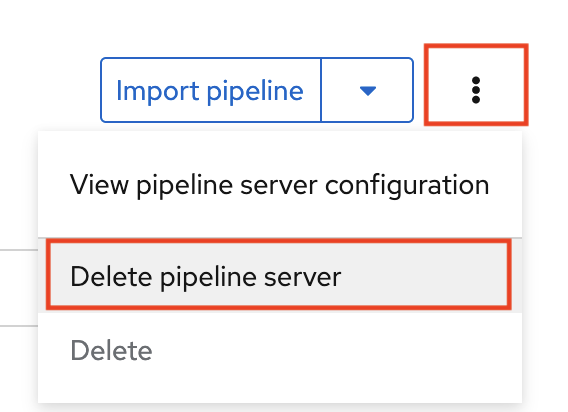
If you have waited more than 5 minutes, and the pipeline server configuration does not complete, you can delete the pipeline server and create it again.
You can also ask your OpenShift AI administrator to verify that they applied self-signed certificates on your cluster as described in Working with certificates (Self-Managed) or Working with certificates (Cloud Service).
-
Navigate to the Pipelines tab for the project.
-
Next to Import pipeline, click the action menu (⋮) and then select View pipeline server configuration.
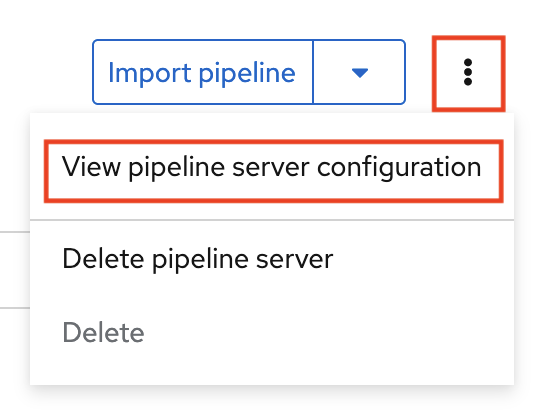
An information box opens and displays the object storage connection information for the pipeline server.