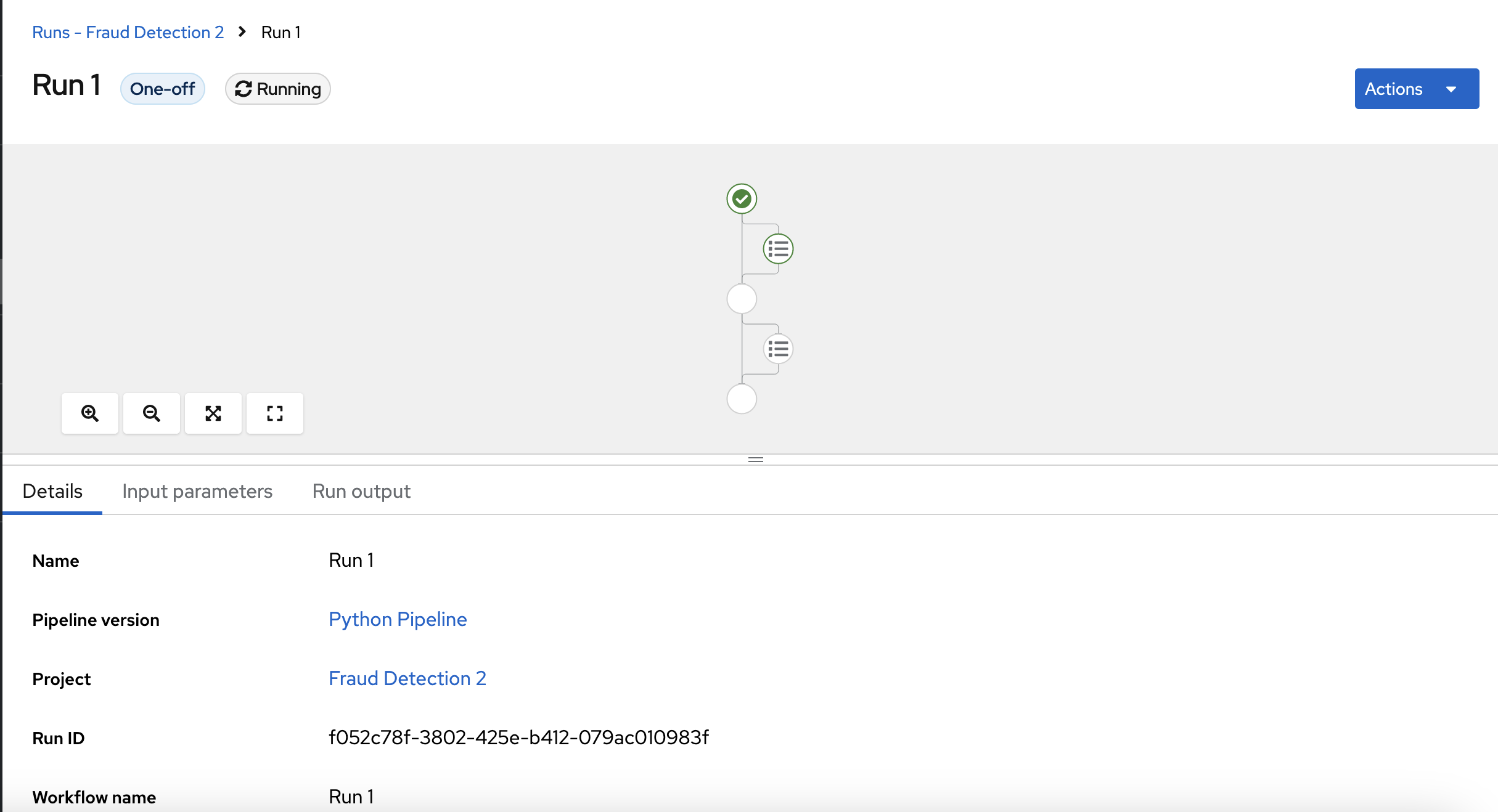
Running a pipeline generated from Python code
Earlier, you created a simple pipeline by using the GUI pipeline editor. You might want to create pipelines by using code that can be version-controlled and shared with others. The Kubeflow pipelines (kfp) SDK provides a Python API for creating pipelines. The SDK is available as a Python package. With this package, you can use Python code to create a pipeline and then compile it to YAML format. Then you can import the YAML code into OpenShift AI.
This workshop does not describe the details of how to use the SDK. Instead, it provides the files for you to view and upload.
-
Optionally, view the provided Python code in your JupyterLab environment by navigating to the
fraud-detection-notebooksproject’spipelinedirectory. It contains the following files:-
5_get_data_train_upload.pyis the main pipeline code. -
build.shis a script that builds the pipeline and creates the YAML file.For your convenience, the output of the
build.shscript is provided in the5_get_data_train_upload.yamlfile. The5_get_data_train_upload.yamloutput file is located in the top-levelfraud-detectiondirectory.
-
-
Right-click the
5_get_data_train_upload.yamlfile and then click Download. -
Upload the
5_get_data_train_upload.yamlfile to OpenShift AI.-
In the OpenShift AI dashboard, navigate to your project page. Click the Pipelines tab and then click Import pipeline.
-
Enter values for Pipeline name and Pipeline description.
-
Click Upload and then select
5_get_data_train_upload.yamlfrom your local files to upload the pipeline.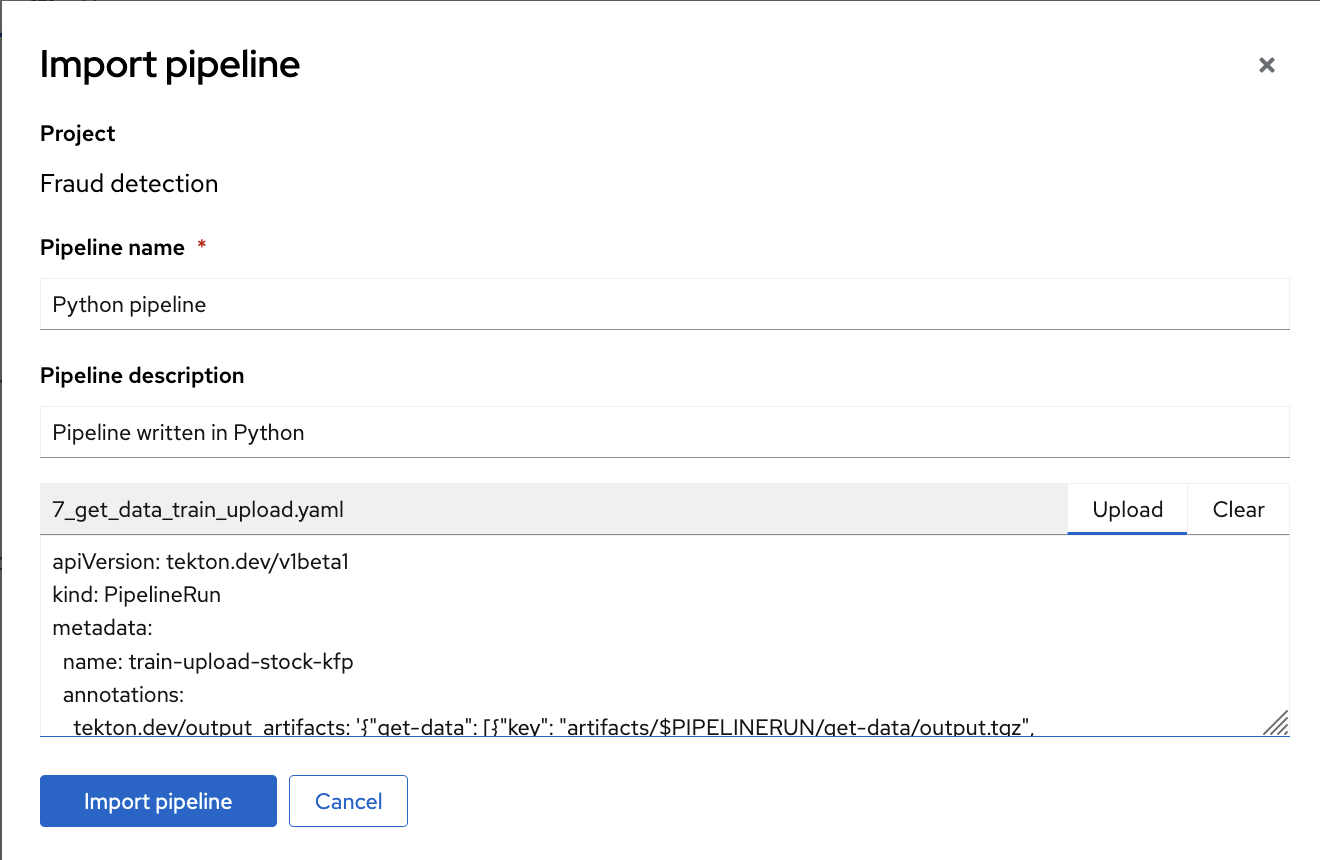
-
Click Import pipeline to import and save the pipeline.
The pipeline shows in graphic view.
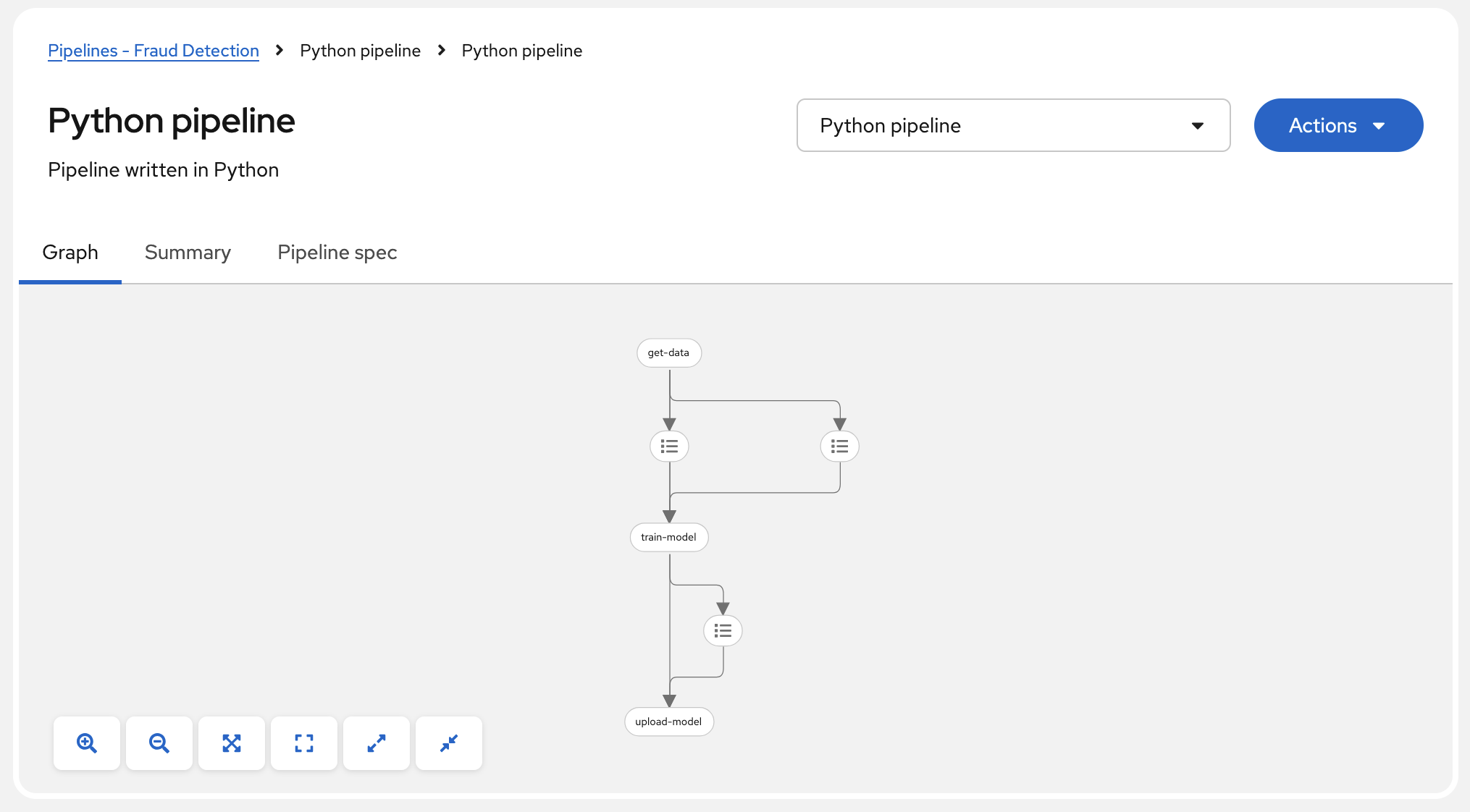
-
-
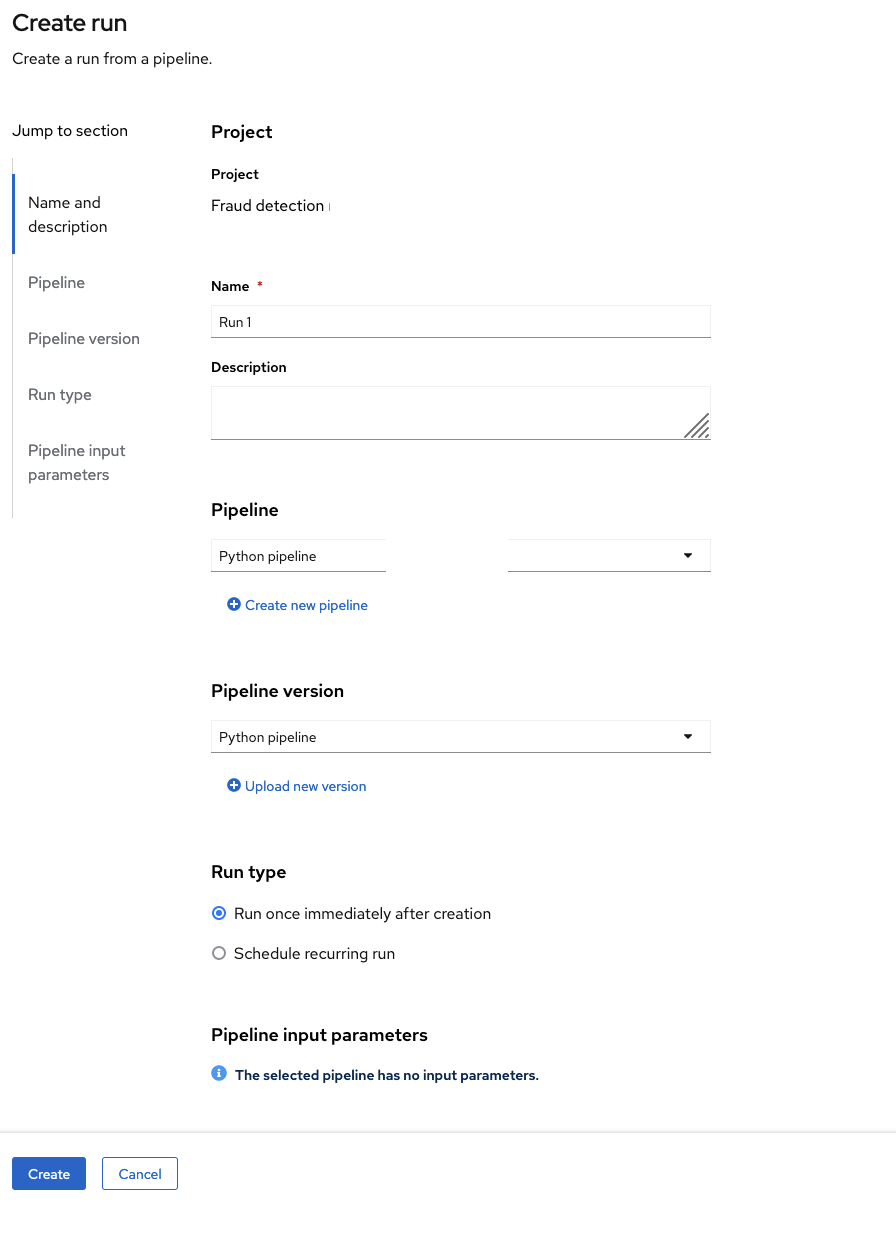
Select Actions → Create run.
-
On the Create run page, provide the following values:
-
For Experiment, leave the value as
Default. -
For Name, type any name, for example
Run 1. -
For Pipeline, select the pipeline that you uploaded.
You can leave the other fields with their default values.
-
-
Click Create run to create the run.
-
A new run starts immediately.