Distributing training jobs with the Training Operator
In previous sections of this workshop, you trained the fraud detection model directly in a notebook and then in a pipeline. In this section, you learn how to train the model by using the Training Operator. The Training Operator is a tool for scalable distributed training of machine learning (ML) models created with various ML frameworks, such as PyTorch.
You can use the Training Operator to distribute the training of a machine learning model across many hardware resources. While distributed training is not necessary for a simple model, applying it to the example fraud detection model is a good way for you to learn how to use distributed training for more complex models that require more compute power, such as many GPUs across many machines.
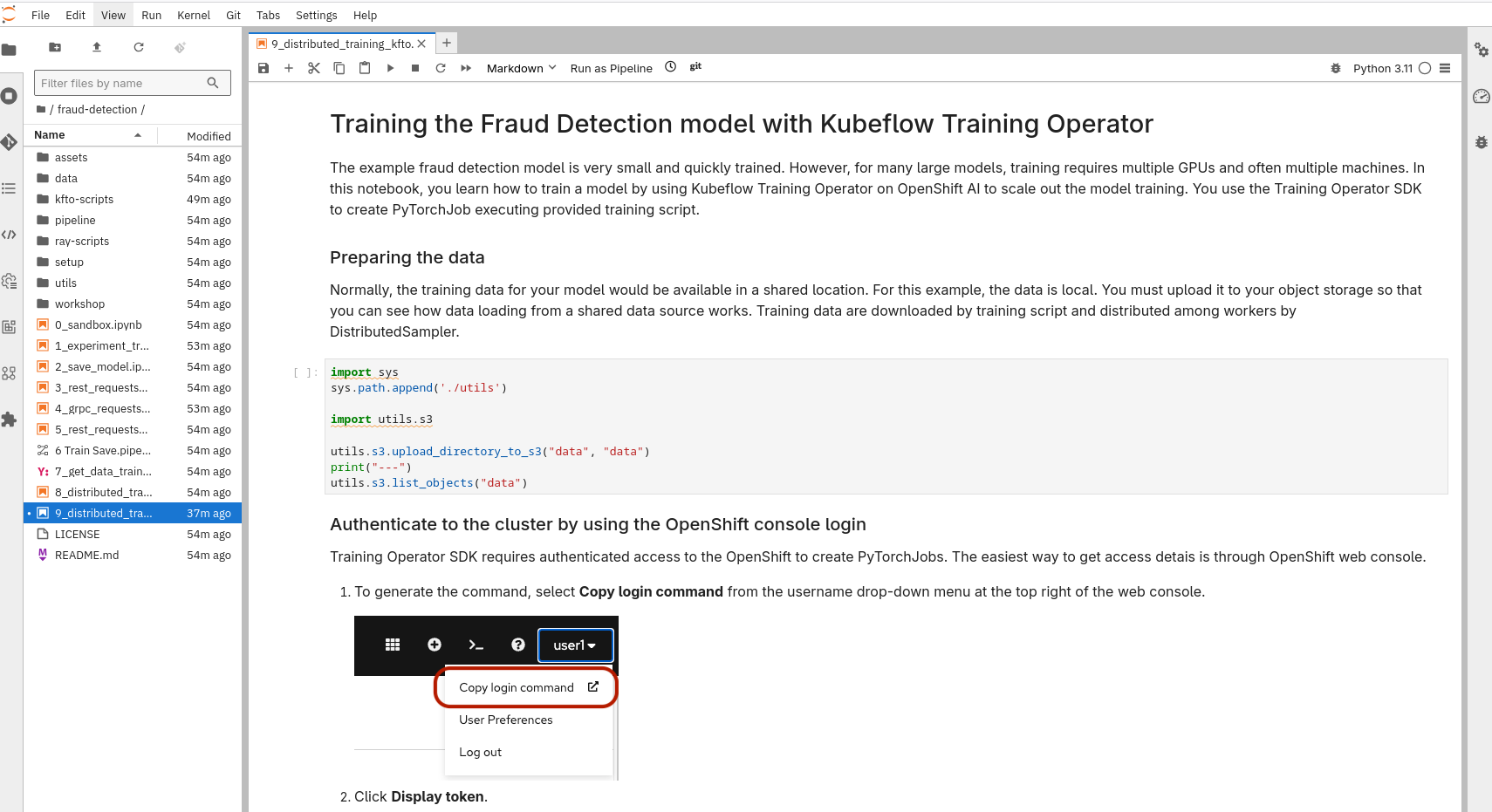
In your notebook environment, open the 9_distributed_training_kfto.ipynb file and follow the instructions directly in the notebook. The instructions guide you through setting authentication, initializing the Training Operator client, and submitting a PyTorchJob.
Optionally, if you want to view the Python code for this section, you can find it in the kfto-scripts/train_pytorch_cpu.py file.
For more information about PyTorchJob training with the Training Operator, see the Training operator PyTorchJob guide.