Llama-Stack Playground
Goal
This module introduces the Llama-Stack Playground, a user-friendly interface designed to demonstrate the core capabilities of Llama Stack in an interactive environment. The dashboard allows you to inspect API providers and resources exposed by Llama Stack.
Prerequisites
Before starting, ensure you have the following:
-
A running Llama Stack server (see: Llama-Stack Hello World)
-
Python 3.10 or newer (to install and run the CLI tools)
Step 1: Deploy the Llama-Stack Playground
You can deploy the playground using the source code or run the pre-built container image from Quay.io:
podman run -p 8322:8322 --network host \
-e LLAMA_STACK_BACKEND_URL=http://localhost:8321 \
quay.io/rh-aiservices-bu/llama-stack-playground:0.2.18podman run -p 8322:8322 \
-e LLAMA_STACK_BACKEND_URL=http://host.containers.internal:8321 \
quay.io/rh-aiservices-bu/llama-stack-playground:0.2.18Once the container is running, the Llama-Stack playground will be available at http://localhost:8322.
Step 2: Interact with the Playground Chat
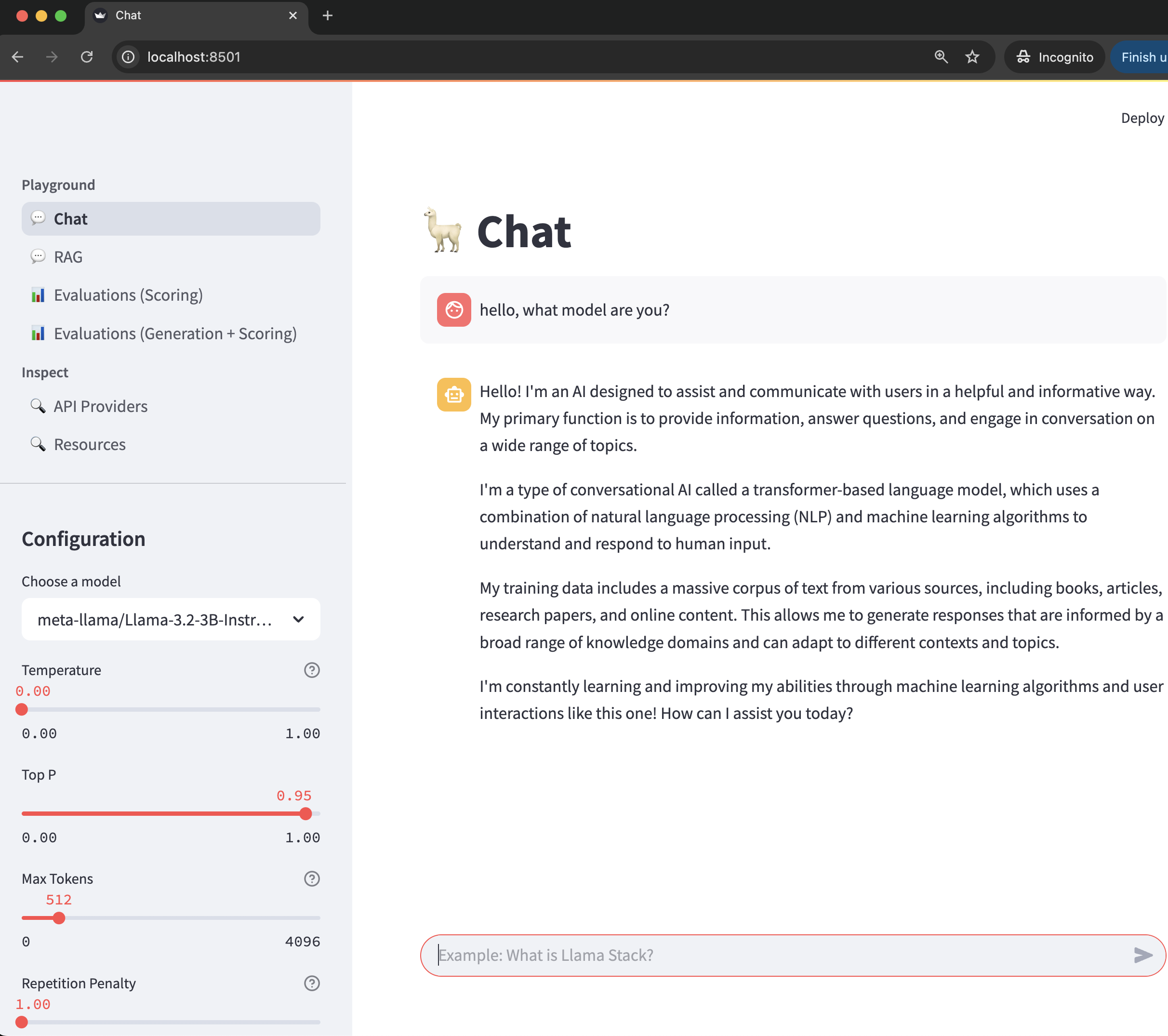
The Llama-Stack Playground is built with TypeScript and includes a chat interface for interacting with the Llama Stack server.
Open your browser and navigate to http://localhost:8322/chat-playground. You’ll see a chat interface where you can enter prompts and receive responses from the deployed LLM model.
Summary
In this module, you:
-
Deployed and launched the Llama-Stack Playground
-
Interacted with the LLM model through the chat interface
-
Explored available models, providers, and other resources
Next, continue with Llama-Stack Python Programming to write and run your first Python program using Llama Stack.